
Gemini Embedding 2は、テキストだけでなく画像、動画、音声、PDFまで同じベクトル空間で扱えるGoogleのマルチモーダル埋め込みモデルです。RAGや社内検索を作る企業にとって魅力的ですが、OpenAI、Voyage、Amazon Nova系Embeddingと比べて常に最適とは限りません。本記事では、性能、価格、対応範囲、制限、導入判断の観点から違いを整理します。
導入:Gemini Embedding 2は「マルチモーダル検索」を前提にした埋め込みモデル
Gemini Embedding 2の最大の特徴は、テキスト、画像、動画、音声、PDFを単一の埋め込み空間にマッピングできる点です。従来のRAGでは、PDFをOCRでテキスト化し、動画をフレーム抽出し、音声を文字起こししてから別々に検索基盤へ投入する設計が一般的でした。
これに対してGemini Embedding 2は、複数モダリティを同じ意味空間に寄せることで、「この説明に近い画像を探す」「この動画の場面に近い資料を探す」「PDF内の図表を自然文で検索する」といったクロスモーダル検索を作りやすくします。
結論から言えば、Gemini Embedding 2は、画像・動画・音声・PDFを横断する検索基盤を作りたい組織に向いています。一方で、テキストだけのFAQ検索やコスト最優先のRAGでは、OpenAIのtext-embedding-3-smallや既存のテキスト専用Embeddingの方が現実的な場合もあります。
何が発表されたのか:Public PreviewからGAへ進んだGemini Embedding 2
Googleは2026年3月10日、Geminiアーキテクチャを基盤にした初のネイティブ・マルチモーダル埋め込みモデルとしてGemini Embedding 2を発表しました。Google公式ブログでは、テキスト、画像、動画、音声、ドキュメントを単一の埋め込み空間にマッピングし、RAG、セマンティック検索、分類、クラスタリングに使えると説明されています。詳細はGoogle公式ブログの発表で確認できます。
その後、Google Cloudのモデルページでは、モデルIDはgemini-embedding-2、リリース日は2026年4月22日、ステータスはGAとして掲載されています。仕様上は、最大入力トークン数8,192、出力次元は最大3,072、MRLにより小さな次元数も選べる設計です。仕様の詳細はGoogle CloudのGemini Embedding 2モデルページに整理されています。
対応入力は、テキスト、画像、音声、動画、PDFです。Google Cloudの仕様では、画像は最大6枚、PDFは最大1ファイル・最大6ページ、音声は最大180秒、動画は音声付きで8,192トークン相当、目安として1fpsで約81秒までとされています。これは「長尺の動画や大量ページPDFを丸ごと一括投入するモデル」ではなく、検索単位に分割して使うモデルだと理解した方が実務上は安全です。
背景:なぜEmbeddingモデルの比較が重要になっているのか
生成AIアプリケーションの精度は、LLM本体だけでなく「どの情報を検索してLLMに渡すか」に大きく左右されます。Embeddingモデルは、文章や画像などの内容を数値ベクトルに変換し、意味的に近い情報を検索するための土台です。RAG、社内ナレッジ検索、ECの商品検索、メディアアーカイブ、法務文書検索では、Embeddingの品質が検索結果の品質を左右します。
これまで多くの企業では、テキストはOpenAIやGoogleのテキストEmbedding、画像はCLIP系、音声は文字起こし後にテキストEmbedding、動画はフレーム抽出と説明文生成を組み合わせるなど、モダリティごとに別パイプラインを組む必要がありました。この方法は柔軟ですが、実装が複雑で、ベクトル空間の整合性やメタデータ設計が難しくなります。
Gemini Embedding 2、Voyage multimodal系、Amazon Nova Multimodal Embeddingsのようなモデルが注目されるのは、この複雑さを減らせる可能性があるためです。ただし、各社の対象モダリティ、料金体系、API制限、ベクトルDBとの相性は異なります。モデル名だけで選ぶのではなく、自社データの種類と検索体験から逆算する必要があります。
Gemini Embedding 2で何ができるようになるのか
Gemini Embedding 2で大きく変わるのは、検索対象をテキスト中心からマルチモーダル中心へ広げられることです。たとえば、社内マニュアルに文章、スクリーンショット、図表、PDF、動画説明が混在している場合でも、それらを同じ検索基盤の中で扱いやすくなります。
従来は「動画を文字起こししてから検索」「PDFをOCRしてから検索」「画像には人手でタグを付けて検索」という設計が多く、視覚的な情報や音声のニュアンスが失われがちでした。Gemini Embedding 2は、少なくとも設計思想として、こうした前処理の一部をモデル側に寄せることで、検索パイプラインを簡素化できます。
具体的な活用例としては、製造業の作業手順動画検索、ECの商品画像検索、マーケティング資料内の図表検索、法務・監査向けのPDFページ検索、メディア企業の過去映像検索などが考えられます。Google DeepMindのモデルページでも、マルチモーダル検索、分類、クラスタリング、レコメンデーションへの利用が示されています。詳細はGoogle DeepMindのGemini Embedding 2紹介ページを参照してください。
既存競合との比較
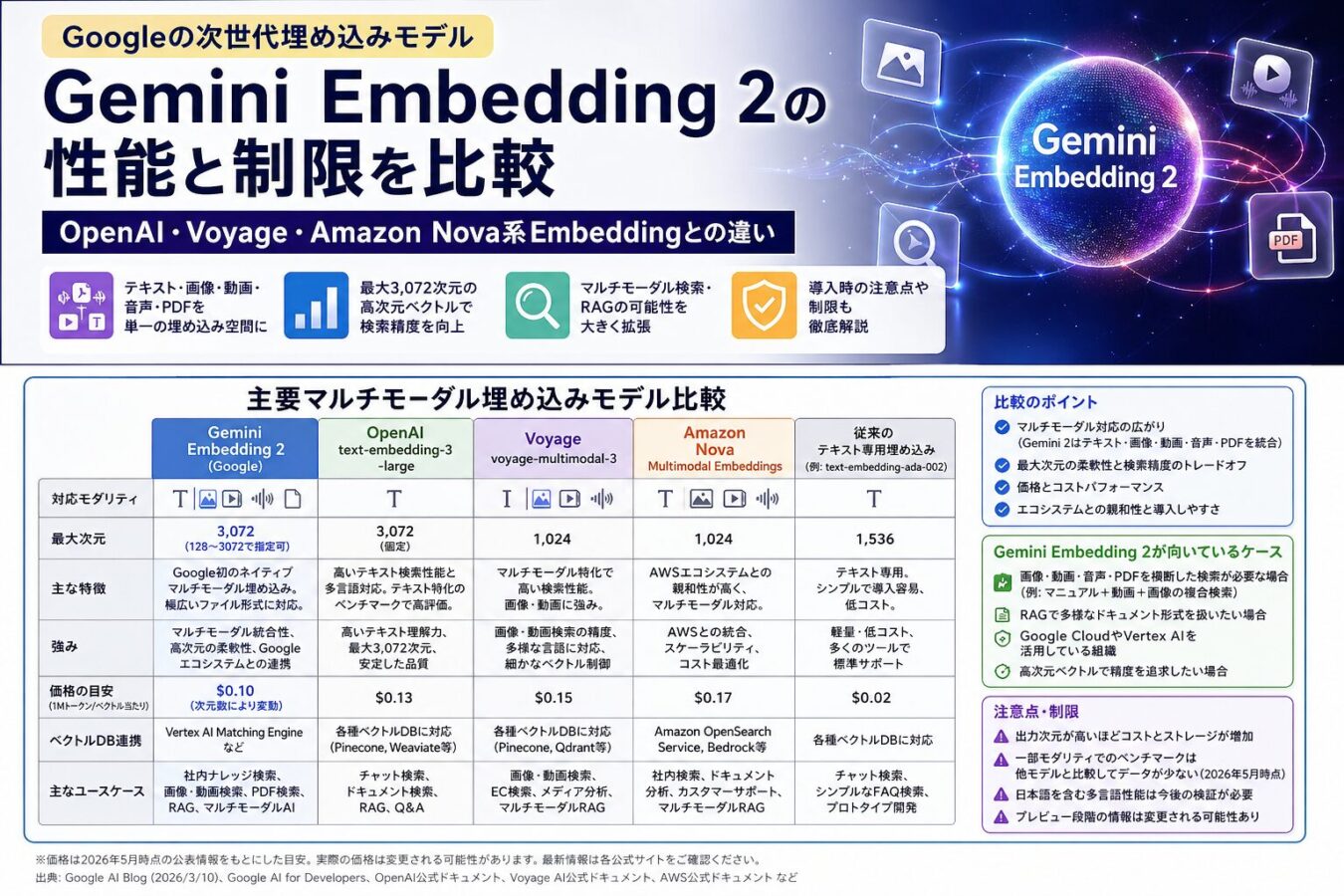
Gemini Embedding 2を評価する際は、単純に「精度が高いか」だけでなく、対応モダリティ、価格、用途、導入しやすさ、制限、安全性、将来性を分けて見る必要があります。ここではOpenAI、Voyage、Amazon Nova系Embeddingと比較します。
| 比較項目 | Gemini Embedding 2 | OpenAI text-embedding-3系 | Voyage multimodal系 | Amazon Nova Multimodal Embeddings |
|---|---|---|---|---|
| 主な用途 | マルチモーダルRAG、社内検索、画像・動画・音声・PDF検索 | テキスト検索、FAQ検索、チャットボットRAG、分類 | 文書画像、スライド、図表、画像を含むRAG | AWS上のマルチモーダル検索、Agentic RAG、メディア検索 |
| 対応モダリティ | テキスト、画像、動画、音声、PDF | テキスト中心。公式モデルページでは画像、音声、動画は非対応 | テキスト、画像、文書スクリーンショット、スライド、図表、動画など | テキスト、ドキュメント、画像、動画、音声 |
| 最大次元 | 最大3,072次元。128〜3,072の柔軟な出力に対応 | text-embedding-3-largeは最大3,072次元 | voyage-multimodal-3.5は1,024次元が標準、256・512・2,048も選択可能 | 3,072、1,024、384、256から選択可能 |
| 価格の見方 | テキストはトークン、画像は画像単位、動画はフレーム単位、音声は秒単位で見る必要がある | text-embedding-3-largeは100万トークンあたり0.13ドル、smallは0.02ドル | テキストトークンと画像・動画のピクセル量に基づく | Bedrock側の料金体系、リージョン、周辺サービス費用を含めて確認が必要 |
| 導入しやすさ | Google Cloud、Vertex AI、Gemini API利用企業と相性が良い | 既存RAGツール、ベクトルDB、サンプル実装が豊富 | 検索・RAG特化の評価がしやすく、文書画像系に強い | AWS、S3、OpenSearch、Bedrock Knowledge Basesとの統合を重視する組織に向く |
| 主な制限 | PDFページ数、音声長、動画長、画像枚数など入力制限を前提に分割設計が必要 | 画像・音声・動画を直接扱えないため、別処理が必要 | 音声対応やGoogle/AWS標準サービスとの統合は用途次第で確認が必要 | 音声検索には制限があり、用途によってBedrock Data Automation併用が推奨される |
OpenAIとの違い:テキストRAGならOpenAI、マルチモーダルならGeminiが有利になりやすい
OpenAIのtext-embedding-3-smallとtext-embedding-3-largeは、テキスト検索や分類で使いやすい埋め込みモデルです。OpenAI公式ドキュメントでは、これらのモデルは低コスト、高い多言語性能、出力サイズ制御を特徴として説明されています。詳しくはOpenAIのEmbeddingsガイドを参照できます。
価格面では、OpenAIのモデルページでtext-embedding-3-largeが100万トークンあたり0.13ドル、text-embedding-3-smallが0.02ドルと示されています。公式モデルページでは、画像、音声、動画は非対応とされているため、マルチモーダル検索を行うには別モデルや前処理を組み合わせる必要があります。料金と対応モダリティはOpenAIのtext-embedding-3-largeモデルページで確認できます。
したがって、FAQ検索、ヘルプセンター検索、議事録検索、チャットボットRAGのように入力がほぼテキストなら、OpenAIは低コストで堅実な選択肢です。一方、画像、PDFの図表、動画、音声まで同じ検索体験に含めたい場合は、Gemini Embedding 2の方が設計を単純化しやすくなります。
Voyageとの違い:文書画像・図表検索では強力な競合
VoyageのマルチモーダルEmbeddingは、テキストとコンテンツリッチな画像、PDFスクリーンショット、スライド、表、図などを扱う検索・RAG用途に強みがあります。Voyage公式ドキュメントでは、voyage-multimodal-3.5は32,000トークンのコンテキスト長、標準1,024次元、256・512・2,048次元の選択肢を持つモデルとして説明されています。詳細はVoyageのMultimodal Embeddingsドキュメントを参照してください。
Gemini Embedding 2とVoyageを比べると、GeminiはGoogleエコシステムと音声・動画・PDFを含む広いモダリティ対応が魅力です。一方、Voyageは検索・RAG特化のモデル選択肢が豊富で、文書画像やスライド、表を含むナレッジ検索では検証候補から外しにくい存在です。
料金体系にも違いがあります。Voyageはマルチモーダルエンドポイントについて、テキストはトークン、画像や動画はピクセル量に基づく課金と説明しています。無料枠もありますが、動画や大量画像を扱う場合は実データで概算を出す必要があります。料金の詳細はVoyageのPricingページで確認できます。
Amazon Novaとの違い:AWS基盤ならNovaも有力
Amazon Nova Multimodal Embeddingsは、Amazon Bedrockで提供されるマルチモーダル埋め込みモデルです。AWS公式ドキュメントでは、テキスト、ドキュメント、画像、動画、音声を単一モデルで扱い、クロスモーダル検索に対応すると説明されています。主な仕様はAmazon Nova Embeddingsのユーザーガイドに掲載されています。
Novaの特徴は、AWS上での運用と統合です。S3にあるファイル、Bedrock、OpenSearch、Knowledge Basesなどを使う企業にとっては、Geminiよりも運用設計が自然になる場合があります。また、Novaは同期・非同期API、長い入力のセグメント化、動画と音声を同時に処理する設定、用途別のembeddingPurposeを持つ点が実務的です。
ただし、AWSのBedrock Knowledge Basesドキュメントでは、Amazon Nova embedding v1.0は音声・動画データ内の音声コンテンツ検索に限定的なサポートとされ、必要に応じてBedrock Data Automationの利用が案内されています。音声検索を主要機能にする場合は、Bedrock Knowledge Basesのマルチモーダル作成ガイドも確認すべきです。
性能比較:Google公表値は強いが、自社データ検証は不可欠
Google DeepMindのモデルページでは、Gemini Embedding 2が複数のクロスモーダルベンチマークで高い結果を示したとされています。たとえば、TextCapsのテキスト→画像検索ではGemini Embedding 2がrecall@1で89.6、Amazon Nova 2 Multimodal Embeddingsが76.0、Voyage Multimodal 3.5が79.4と掲載されています。
一方で、Text-DocumentのViDoRe v2 ndcg@10ではGemini Embedding 2が64.9、Amazon Novaが60.6、Voyageが65.5とされ、Voyageの値が上回る項目もあります。つまり、Gemini Embedding 2は広い範囲で強い候補ですが、すべての用途で常に最良というわけではありません。
また、ベンチマークはデータセット、評価条件、モダリティ、前処理、ベクトルDB、再ランキングの有無によって結果が変わります。企業導入では、公開ベンチマークを参考にしつつ、自社データでRecall@k、nDCG、ヒット率、検索遅延、誤検索パターンを測ることが重要です。
懸念点・注意点
Gemini Embedding 2の最初の注意点は、入力制限です。PDFは最大6ページ、画像は最大6枚、音声は最大180秒、動画も長尺をそのまま扱う設計ではありません。現実の社内資料や動画アーカイブでは、チャンク分割、ページ分割、動画クリップ化、メタデータ付与が必要になります。
2つ目は、コストの見積もりです。テキストだけのRAGならトークン数で概算しやすいですが、マルチモーダルでは画像数、動画フレーム数、音声秒数が効いてきます。Google Cloudの料金ページでは、Gemini Embedding 2についてテキストは100万トークンあたり0.2ドル、画像は1枚あたり0.00012ドル、動画は1フレームあたり0.00079ドル、音声は1秒あたり0.00016ドル、出力課金なしと掲載されています。ただし、料金ページ側にPreview表記が残っている場合もあるため、契約時点のSKU確認は必須です。料金はGoogle CloudのAgent Platform Pricingで確認できます。
3つ目は、ベンダーロックインです。Embeddingモデルを変更すると、既存コーパス全体の再Embedding、ベクトルインデックス再構築、検索品質の再評価が必要になります。AWSの実践ガイドでも、Embeddingモデル選定は慎重に行うべきだと説明されています。これはGoogle、OpenAI、Voyage、AWSのどれを選ぶ場合でも共通する注意点です。
4つ目は、安全性と権限管理です。画像、PDF、音声、動画まで検索対象に含めると、個人情報、機密図面、契約書、音声会議などが検索結果に露出する可能性があります。単にベクトル化するだけでなく、検索前後の権限制御、監査ログ、データ保持ポリシー、削除要求への対応を設計に含める必要があります。
導入メリットを得やすい人・組織
Gemini Embedding 2が向いている人
Gemini Embedding 2が向いているのは、テキスト以外の情報が検索品質を大きく左右する組織です。たとえば、製品マニュアルにスクリーンショットが多いSaaS企業、動画教材を大量に持つ教育事業者、過去映像を検索したいメディア企業、PDFの図表や添付画像を含む法務・監査資料を扱う企業が該当します。
また、Google CloudやVertex AIをすでに使っている組織も導入メリットを得やすいでしょう。既存の認証、ログ、データ基盤、Vertex AIとの接続を活かしながら、マルチモーダルRAGを検証できます。Googleエコシステム内でAI検索基盤を整えたい企業にとっては、運用面の整合性があります。
特に相性が良いのは、「自然文で画像・動画・PDFを探したい」という検索体験を提供したいケースです。従来は人手タグ、OCR、文字起こし、画像説明生成などを組み合わせていた処理を、より統一的なベクトル検索に寄せられる可能性があります。
現時点では向いていない人
一方で、問い合わせFAQ、ヘルプ記事、社内規程など、検索対象がほぼテキストだけなら、Gemini Embedding 2を最初から選ぶ必要はありません。OpenAIのtext-embedding-3-small、Googleのテキスト専用Embedding、OSS系Embeddingなどを使った方が、コストや構成がシンプルになる可能性があります。
また、数百ページのPDFをそのまま投入したい、数時間の動画を一括で検索対象化したい、音声会議の発話内容を高精度に検索したいといった用途では、Gemini Embedding 2単体で完結しません。事前分割、文字起こし、OCR、メタデータ設計、場合によっては再ランキングモデルが必要です。
さらに、マルチクラウド方針で特定ベンダー依存を避けたい組織、AWSに標準化している組織、検索・RAGの評価基盤がVoyageやOpenAIで既に安定している組織は、急いで移行するよりも並行検証から始める方が安全です。
実務導入を判断する際のポイント
まず確認したい前提条件
導入前に最初に確認すべきなのは、検索対象データの構成です。テキストが9割以上なのか、PDFの図表が多いのか、動画や音声が検索価値の中心なのかによって、最適なEmbeddingモデルは変わります。モデル比較より先に、データ棚卸しを行うべきです。
次に、検索クエリの種類を確認します。ユーザーが自然文で文章を探すだけならテキストEmbeddingで十分な場合があります。一方、「この画像に似た商品」「この動画の場面」「この図表が載っている資料」のような検索が必要なら、マルチモーダルEmbeddingを検討する価値があります。
導入判断で見るべきポイント
- 精度:公開ベンチマークではなく、自社データでRecall@5、Recall@10、nDCG、誤検索率を測る。
- コスト:テキストのトークン数だけでなく、画像枚数、動画フレーム、音声秒数、再Embedding頻度を含める。
- 再現性:同じクエリで安定して同じ候補が出るか、更新後に検索品質が崩れないかを確認する。
- 既存システム接続性:Vertex AI、Bedrock、既存ベクトルDB、認証基盤、監査ログとの相性を見る。
- データ取り扱い:個人情報、契約書、音声、動画の保存場所、削除手順、権限制御を事前に決める。
試験導入から本格導入までの見方
試験導入では、いきなり全社データを対象にせず、1つの業務領域に絞るのが現実的です。たとえば、製品マニュアル100件、動画クリップ500本、PDF資料1,000ページ相当など、評価可能な範囲でコーパスを作ります。
そのうえで、Gemini Embedding 2、OpenAI、Voyage、Amazon Novaの候補を同じ検索質問セットで比較します。検索結果の上位10件を人間が評価し、正解候補が何位に出るか、不要な結果が混ざる理由は何か、再ランキングが必要かを見ます。
本格導入では、モデルそのものよりも運用設計が重要になります。データ更新時の再Embedding、失敗時の再試行、ベクトルDBの容量、権限制御、検索ログ分析、ユーザーからのフィードバック収集まで含めて設計しなければ、初期精度が高くても継続運用で品質が下がります。
導入を急がなくてよいケース
検索対象がテキスト中心で、現在のRAG精度に大きな不満がない場合は、急いでGemini Embedding 2へ移行する必要はありません。まずは検索ログを分析し、問題がEmbedding由来なのか、チャンク設計、メタデータ、プロンプト、再ランキングの問題なのかを切り分けるべきです。
また、動画や音声を扱う予定がまだない段階で、将来性だけを理由にマルチモーダルEmbeddingを選ぶと、コストや運用が過剰になる可能性があります。今後のデータ種別が不確定な場合は、PoCで比較し、既存構成を維持しながら段階的に試すのが安全です。
よくある質問
Gemini Embedding 2はOpenAIのEmbeddingより高性能ですか?
用途によります。画像、動画、音声、PDFを含むマルチモーダル検索ではGemini Embedding 2の方が設計上有利になりやすいです。一方、テキストだけのRAGではOpenAIのtext-embedding-3-smallやlargeも実績があり、コストや既存ツール連携の面で有利な場合があります。公開ベンチマークだけでなく、自社データで評価することが重要です。
Gemini Embedding 2はPDFを丸ごと検索できますか?
PDF入力には対応していますが、Google Cloudの仕様では最大1ファイル・最大6ページという制限があります。そのため、数十ページから数百ページのPDFをそのまま一度に投入する用途には向きません。実務ではページ単位や章単位に分割し、タイトル、ページ番号、文書種別などのメタデータを付けてベクトルDBに保存する設計が必要です。
動画検索にはGemini Embedding 2とAmazon Novaのどちらが向いていますか?
Google CloudやVertex AIを中心に使うならGemini Embedding 2、AWSとBedrockを中心に使うならAmazon Novaが自然な候補です。性能面では公開ベンチマークを参考にできますが、実務では動画の長さ、分割単位、音声を検索対象に含めるか、S3や既存メディア管理基盤との連携を含めて比較する必要があります。
Voyage multimodal系はGemini Embedding 2の競合になりますか?
なります。特にPDFスクリーンショット、スライド、表、図表など、視覚情報を含む文書検索ではVoyageは強力な候補です。Gemini Embedding 2は音声・動画・PDFを含む広いモダリティ対応とGoogle連携が強みで、Voyageは検索・RAG特化のモデル選択肢と文書画像系の使いやすさが魅力です。どちらが良いかはデータ種別で変わります。
Gemini Embedding 2を使えばOCRや文字起こしは不要になりますか?
完全に不要になるとは限りません。Gemini Embedding 2は文書OCRや音声・動画の理解を取り込んだ設計ですが、検索結果の説明、監査、引用、正確な本文表示が必要な業務では、OCRテキストや文字起こしテキストを別途保持した方が安全です。Embeddingは検索候補を探す技術であり、根拠提示や全文検索をすべて置き換えるものではありません。
最初のPoCでは何を比較すべきですか?
まず同じデータセットと同じ質問リストで、Gemini Embedding 2、OpenAI、Voyage、Amazon Novaの候補を比較します。見るべき指標は、正解が上位何件に入るか、誤検索の理由、検索速度、Embedding作成コスト、ベクトルDB容量、再Embeddingの手間です。特にマルチモーダルでは、画像や動画の分割設計が結果に大きく影響します。
まとめ:Gemini Embedding 2は「広い対応範囲」が強み、ただし選定は用途次第
Gemini Embedding 2は、Googleのマルチモーダル検索戦略を象徴するEmbeddingモデルです。テキスト、画像、動画、音声、PDFを単一の埋め込み空間で扱えるため、従来のテキスト中心RAGでは拾いにくかった情報を検索対象にしやすくなります。
一方で、テキストだけのRAGならOpenAIのtext-embedding-3系、文書画像や図表検索ではVoyage、AWS統合を重視するならAmazon Novaが有力です。Gemini Embedding 2は「何でも扱えるから最適」ではなく、「複数モダリティを横断する検索体験を作りたい場合に強い」と捉えるのが現実的です。
導入を検討する企業は、モデル名やベンチマークだけで判断せず、自社データ、検索クエリ、コスト、運用体制、権限制御を含めて比較すべきです。特にEmbeddingモデルは後から変更すると再Embeddingと評価やり直しが発生するため、小さなPoCで検索品質と運用負荷を確認してから本格導入へ進むのが安全です。
参考ソース
- Google公式ブログ:Gemini Embedding 2発表
- Google Cloud:Gemini Embedding 2モデル仕様
- Google DeepMind:Gemini Embedding 2モデル情報とベンチマーク
- OpenAI:Embeddingsガイド
- OpenAI:text-embedding-3-largeモデルページ
- Voyage AI:Multimodal Embeddingsドキュメント
- Voyage AI:Pricing
- AWS:Amazon Nova Embeddingsユーザーガイド
- AWS:Bedrock Knowledge Basesマルチモーダル作成ガイド
- AWS公式ブログ:Amazon Nova Multimodal Embeddings実践ガイド

コメント