
Xiaomiが公開した「MiMo-V2.5-Pro」は、単なるチャット向け大規模言語モデルというより、長い文脈を読み続けながら、開発環境や外部ツールを使って複雑な作業を進めるエージェント用途を強く意識したAIモデルです。本記事では、公式情報と主要競合の公開情報をもとに、Claude、Gemini、DeepSeekと比べて何が違うのか、実務で検討する際にどこを見るべきかを整理します。
導入:MiMo-V2.5-Proの結論を先に整理する
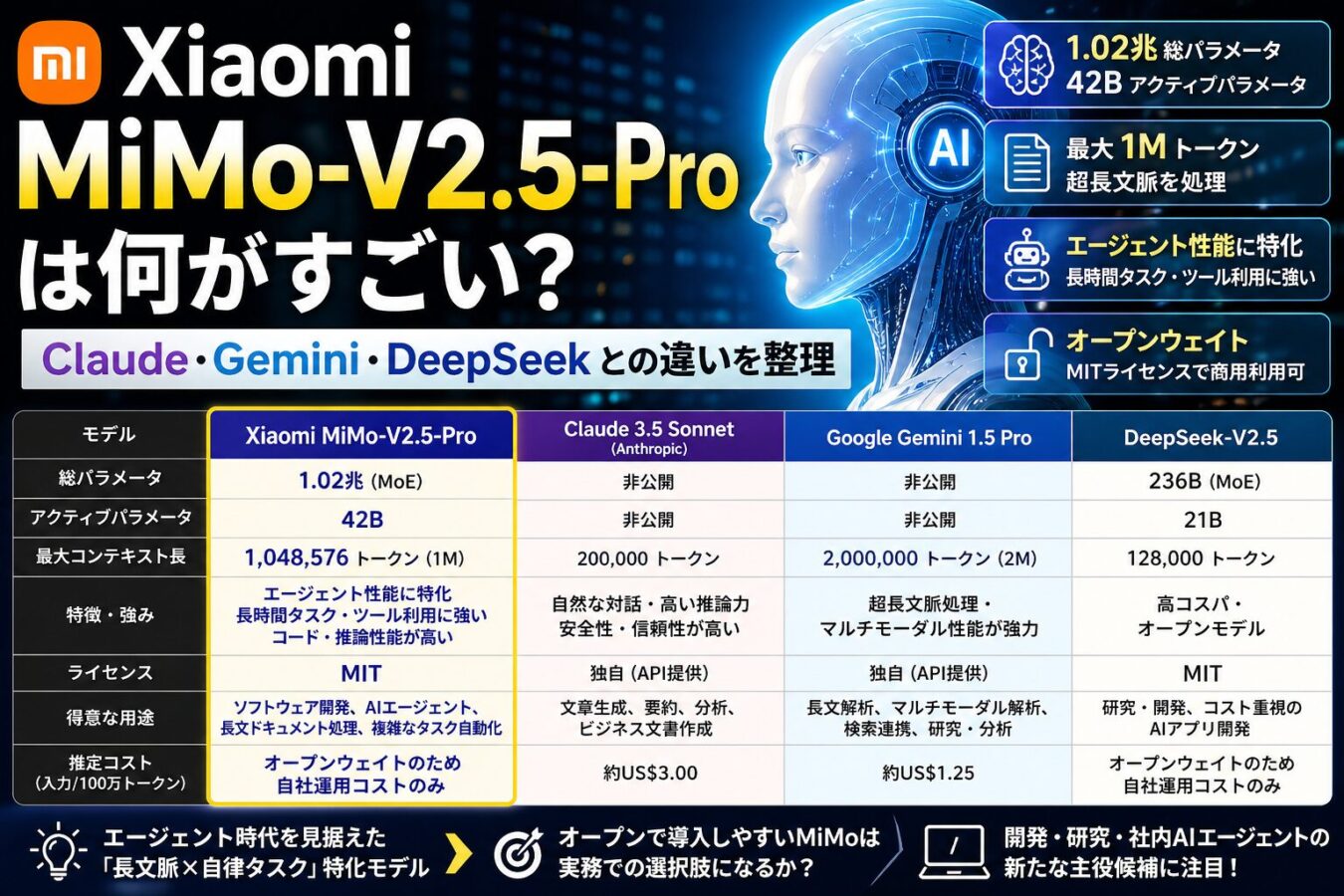
MiMo-V2.5-Proの特徴を一言でいえば、「長時間の自律タスクを低コストで回すためのオープンウェイト系エージェントモデル」です。Xiaomiは公式ページで、同モデルを1.02兆総パラメータ、42Bアクティブパラメータ、最大1Mトークンのコンテキスト長を持つMixture-of-Expertsモデルとして説明しています。
重要なのは、パラメータ数の大きさだけではありません。Xiaomiは、MiMo-V2.5-Proが数百回から千回を超えるツール呼び出しを伴う長い作業で、指示追従性と文脈の一貫性を保つことを重視していると説明しています。つまり、短い質問に高品質に答えるモデルというより、コードベース調査、実装、テスト、修正、再実行といった連続作業に向けたモデルです。
一方で、現時点で「ClaudeやGeminiを全面的に置き換える」と見るのは早計です。Claude Sonnet 4.6やGemini 3.1 Proは、商用API、マルチモーダル、企業向け基盤、既存エコシステムで強みがあります。MiMo-V2.5-Proは、オープンウェイト、長文脈、エージェント実行コストを重視する開発者や企業にとって有力な選択肢になる、というのが現実的な位置づけです。
何が発表されたのか
Xiaomi MiMoチームは、MiMo-V2.5-Proを同社のこれまでで最も高性能なモデルとして公開しました。公式発表では、一般的なエージェント能力、複雑なソフトウェアエンジニアリング、長時間タスクで前世代のMiMo-V2-Proから改善したと説明されています。詳細はXiaomi MiMo-V2.5-Pro公式ページで確認できます。
モデルカードはHugging Faceでも公開されており、ライセンスはMITとされています。モデル仕様としては、1.02T総パラメータ、42Bアクティブパラメータ、最大1Mトークン文脈長、FP8混合精度が示されています。商用利用、改変、ファインチューニングを検討しやすい点は、クローズドAPI中心のモデルと大きく異なります。詳細はHugging FaceのMiMo-V2.5-Proモデルカードに掲載されています。
公式ページで目を引くのは、ベンチマーク表だけではなく、長時間タスクの実例です。Xiaomiは、MiMo-V2.5-ProがRustでSysYコンパイラを実装し、672回のツール呼び出し、4.3時間で233件中233件の隠しテストに合格したと説明しています。また、8,192行のデスクトップ動画編集アプリを1,868回のツール呼び出し、11.5時間の自律作業で生成した例も示しています。
背景:なぜXiaomiのAIモデルが注目されるのか
XiaomiはスマートフォンやEV、IoT製品のイメージが強い企業ですが、2026年に入ってAIへの投資姿勢を明確にしています。Reutersは2026年3月、同社CEOの雷軍氏が今後3年間で少なくとも600億元、米ドル換算で約87億ドルをAIに投資すると述べたと報じました。背景には、中国の生成AI市場で価格競争が進み、単純なチャットよりも高トークン消費のエージェント用途へ関心が移っている流れがあります。参照:ReutersによるXiaomiのAI投資報道。
生成AIの競争軸は、単に「質問への回答が賢いか」から、「どれだけ長く作業を続けられるか」「外部ツールを正しく使えるか」「同じ品質をどのコストで再現できるか」へ広がっています。開発現場では、コード生成だけでなく、リポジトリ理解、依存関係の確認、テスト実行、バグ修正、レビューコメント対応まで一連の流れを自動化するニーズが強まっています。
MiMo-V2.5-Proは、この流れに対して、1Mコンテキスト、MoEによる計算効率、MITライセンス、エージェント向けポストトレーニングを組み合わせて応えようとするモデルです。Xiaomiのスマートデバイス事業と直接連動する話ではありませんが、同社がAIをOS、アプリ、開発者基盤、デバイス群に広げる可能性を考えると、単発の研究公開以上の意味があります。
MiMo-V2.5-Proで何ができるようになるのか
従来のAIモデルでも、コードの一部生成や短いスクリプト作成は可能でした。しかし、実務では「最初のコードを書く」よりも、「仕様を読み、既存コードを理解し、複数ファイルにまたがる変更を行い、失敗したテストから原因を推定し、修正する」ことのほうが時間を使います。MiMo-V2.5-Proが狙っているのは、この後半の複雑な反復作業です。
1Mトークンのコンテキスト長は、大きな設計書、長いログ、複数ファイルのコード、テスト結果、過去の作業履歴をまとめて扱う余地を広げます。もちろん、長い文脈を入れれば必ず正確になるわけではありません。それでも、文脈を分割して人間が要約し直す手間を減らせるため、長時間エージェントの設計では大きな意味があります。
具体的な用途としては、既存リポジトリの調査、レガシーコードの移行、テストケース生成、ドキュメント整備、CIエラーの原因分析、社内ツールの試作、データ処理パイプラインの改修などが考えられます。特に、同じような確認と修正を大量に繰り返す業務では、トークン単価と成功率のバランスが導入判断に直結します。
もう一つのポイントは、オープンウェイトであることです。クローズドAPIでは、モデルの内部や重みを利用者側で直接制御できません。一方、MiMo-V2.5-ProはHugging Faceで重みが公開されているため、十分な計算資源と運用体制があれば、自社環境での実行、追加検証、用途別チューニング、データ取り扱いルールの設計をより細かく検討できます。
既存競合との比較
MiMo-V2.5-Proを理解するには、Claude、Gemini、DeepSeekとの比較が役立ちます。ただし、各社のベンチマーク、API条件、推論モード、コンテキスト長、価格体系は頻繁に変わります。以下は2026年4月29日時点で公開情報から確認できる範囲の比較です。
| モデル | 主な位置づけ | 文脈長 | 価格・運用面 | 向いているケース | 注意点 |
|---|---|---|---|---|---|
| Xiaomi MiMo-V2.5-Pro | 長時間エージェント、複雑なコード作業、オープンウェイト | 最大1Mトークン | MITライセンス。API価格は地域・プランにより変わるため、導入前に公式プラットフォームで確認が必要 | 大量のツール呼び出しを伴う開発エージェント、オンプレミス検証、長文脈処理 | 自前運用には大規模GPU、推論最適化、監視体制が必要。日本語品質や業務別性能は個別検証が必要 |
| Claude Sonnet 4.6 | 商用エージェント、コーディング、長時間作業 | APIでは1Mトークン文脈長がベータ提供 | AnthropicはSonnet 4.6を100万入力トークンあたり3ドル、出力15ドルからと案内 | Claude Codeや企業向けワークフローで安定運用したいケース | クローズドモデルのため重みは利用できない。価格はMiMoやDeepSeek系より高くなりやすい |
| Gemini 3.1 Pro Preview | 高度な推論、マルチモーダル、Googleエコシステム連携 | 入力1M、出力64K | Googleの開発者向け資料では、200K以下で入力2ドル、出力12ドル、200K超で入力4ドル、出力18ドル | テキスト、画像、動画、PDF、コードリポジトリを横断する分析 | Previewモデルであるため仕様や制限が変わる可能性がある。Google基盤への依存も考慮が必要 |
| DeepSeek V4-Pro | オープンモデル系の高性能推論、エージェント、コーディング | 1Mトークン | 公式価格表では、割引適用時に入力キャッシュミス0.435ドル、出力0.87ドル。割引期限がある | 価格重視で高性能な推論・エージェント用途を試したいケース | 価格は割引終了後に変わる。Huawei Ascend最適化や地域・規制面の考慮が必要 |
性能面では、MiMo-V2.5-Proは「開発エージェントの長時間作業」に寄せた主張が目立ちます。Claude Sonnet 4.6も同じくエージェントとコーディングを強く打ち出しており、商用サービスとしての完成度、ツール統合、企業導入のしやすさではClaudeが有利な場面があります。Anthropicの説明はClaude Sonnet 4.6の公式ページとClaude API価格表で確認できます。
Gemini 3.1 Pro Previewは、長文脈に加えてマルチモーダルが強みです。Googleの開発者向け資料では、Gemini 3.1 Proが複雑なタスク、広範な知識、モダリティ横断の高度な推論に向くとされています。文章、画像、動画、PDF、コードをまとめて扱う業務では、MiMo-V2.5-ProよりGeminiを優先すべきケースもあります。参照:Gemini 3 Developer Guide、Gemini API価格表。
DeepSeek V4-Proは、価格とオープンモデル系の性能で比較対象になります。DeepSeekの公式価格表では、V4-Proに75%割引が適用されており、2026年5月31日15:59 UTCまで延長されたと記載されています。一方でReutersは、DeepSeek V4がHuaweiチップ向けに最適化され、中国のAIインフラ自立の文脈で注目されているとも報じています。参照:DeepSeek API価格表、ReutersのDeepSeek V4報道。
結局のところ、MiMo-V2.5-Proの強みは「最高性能を単独で名乗ること」ではなく、オープンウェイト、長文脈、エージェント効率を同時に満たそうとしている点です。ClaudeやGeminiは完成された商用体験、DeepSeekは価格競争力、MiMoはオープンな長時間エージェント基盤という切り分けで見ると、導入判断がしやすくなります。
懸念点・注意点
第一の注意点は、ベンチマークと実務成果は一致しないことです。Xiaomiが示すSysYコンパイラや動画編集アプリの例は印象的ですが、特定のハーネス、評価条件、タスク設計に依存します。自社のコードベース、言語、テスト環境、セキュリティ要件で同じ成果が出るかは別問題です。
第二に、1Mトークンの文脈長は便利である一方、コストと遅延の増加につながります。長い文脈を丸ごと投入する運用は、不要なログや重複ドキュメントまで処理してしまうリスクがあります。実務では、RAG、要約、差分抽出、キャッシュ設計を組み合わせて、必要な情報だけを入れる設計が重要です。
第三に、自前運用の難易度です。MiMo-V2.5-Proはオープンウェイトですが、1.02T総パラメータ、FP8、MoE、1Mコンテキストを実用的な速度で動かすには、推論エンジン、分散実行、GPUメモリ、KVキャッシュ管理、監視、障害対応が必要です。小規模チームがすぐにローカルPCで扱えるモデルではありません。
第四に、データと規制の観点です。APIを使う場合は、入力データがどの地域で処理されるか、ログ保持や学習利用の扱い、契約上の責任範囲を確認する必要があります。自前環境で動かす場合でも、モデル出力の監査、脆弱なコード生成、ライセンス混入、機密情報の扱いを管理しなければなりません。
第五に、日本語や業界特化タスクでの検証不足です。Hugging Faceのモデルカードでは英語・中国語タグが確認できますが、日本語の法務文書、医療、金融、製造業の現場ドキュメントなどで十分な性能があるかは、公開情報だけでは判断できません。導入前に小さな評価セットを作ることが不可欠です。
導入メリットを得やすい人・組織
向いている人・組織
MiMo-V2.5-Proが向いているのは、長いコードベースや大量ドキュメントを扱い、AIに単発回答ではなく連続作業を任せたい組織です。たとえば、モノレポの調査、旧システムから新基盤への移行、テスト自動生成、CI/CDログ分析、複雑な社内ツール開発など、作業が長く、途中の判断が多い領域で価値を出しやすいでしょう。
また、クローズドAPIだけに依存したくない企業にも向いています。モデル重みを検証できること、自社環境での運用可能性があること、MITライセンスで商用利用の自由度が高いことは、データ管理やコスト予測を重視する組織にとって魅力です。特に、高頻度にエージェントを回す開発組織では、トークン単価よりも「成功したタスク1件あたりの総コスト」を下げられる可能性があります。
現時点では向いていない人・組織
一方、すぐに安定したSaaS体験が欲しい組織には、ClaudeやGeminiのほうが扱いやすい場合があります。プロンプト画面、チーム管理、請求、監査、サポート、既存ツール連携まで含めて考えると、モデル性能だけではなく運用体験が重要になるためです。
GPU運用の知見がない、セキュリティレビューの体制がない、評価データを作れない、AI出力を人間が確認する工程を置けない組織では、MiMo-V2.5-Proのオープン性が逆に負担になる可能性があります。オープンウェイトは自由度を与えますが、同時に運用責任も利用者側へ寄ります。
また、マルチモーダル処理を中心に考えている場合も注意が必要です。MiMo-V2.5-Proはエージェントやコード作業に強みを置くモデルとして説明されており、画像、音声、動画をまたぐ業務ではGemini系や別のマルチモーダルモデルを比較対象に入れるべきです。
実務導入を判断する際のポイント
まず確認したい前提条件
最初に確認すべきなのは、AIに任せたい作業が本当に「長時間エージェント」に向いているかです。単発の文章作成や短い問い合わせ対応であれば、MiMo-V2.5-Proの1Mコンテキストや長時間ツール利用は過剰です。逆に、複数手順、複数ファイル、テスト実行、外部ツール連携を伴う業務であれば検討価値があります。
次に、成功条件を数値化する必要があります。たとえば「プルリクエスト作成まで到達した割合」「テストが通った割合」「人間の修正時間」「1タスクあたりの総トークン数」「失敗時の復旧しやすさ」などです。モデルのスコアを見るだけでなく、自社の実作業に近い評価セットを作ることが重要です。
導入判断で見るべきポイント
第一に精度です。コード生成ならコンパイル成功率、テスト通過率、脆弱性混入率、仕様逸脱率を見ます。文章業務なら、根拠の有無、社内用語の扱い、引用の正確性を評価します。特にエージェントでは途中の小さな誤りが後段で大きくなるため、最終出力だけでなく作業ログも見るべきです。
第二に再現性です。同じタスクを何度か実行したとき、毎回似た品質で完了できるかは実務では非常に重要です。温度設定、ツール権限、ファイルアクセス範囲、テスト実行環境を固定し、成功率のばらつきを測る必要があります。
第三にコストです。エージェント運用では、入力単価や出力単価だけでなく、失敗した試行、再実行、ツール呼び出し、ログ保存、キャッシュ、GPU運用費も合算します。MiMo-V2.5-Proを自前運用する場合、API料金は下げられても、GPU・人件費・監視費で総コストが上がる可能性があります。
第四にデータの取り扱いです。社内コード、顧客データ、契約書、障害ログを扱う場合、API送信が許されるのか、自前運用が必要なのかを先に決めるべきです。オープンウェイトの利点はここで効きますが、自社運用ではパッチ適用、アクセス制御、監査ログが必要になります。
第五に障害時の代替手段です。AIエージェントが途中で誤ったファイルを変更した場合、誰が戻すのか。APIが落ちた場合、どのモデルに切り替えるのか。モデル更新で出力傾向が変わった場合、評価基準をどう維持するのか。導入前にロールバック手順を用意しておく必要があります。
試験導入から本格導入までの見方
試験導入では、いきなり本番コードに書き込み権限を与えるのではなく、読み取り専用、サンドボックス、限定リポジトリから始めるべきです。最初の評価対象は、過去に人間が解決したバグ修正、ドキュメント更新、テスト追加などが適しています。正解に近い結果があるため、AIの作業を評価しやすいからです。
次に、MiMo-V2.5-Pro、Claude Sonnet、Gemini、DeepSeekを同じタスクで比較します。見るべきなのは、最終スコアだけではありません。どのモデルが余計な変更を少なく済ませたか、失敗時に自己修正したか、ログを読み違えなかったか、レビューしやすい差分を出したかを確認します。
本格導入は、成功率だけでなく人間の作業時間削減が確認できてからで十分です。AIが一見動いていても、レビュー負担が増えたり、誤修正の検出に時間がかかったりするなら、実質的な生産性は上がっていません。
導入を急がなくてよいケース
導入を急がなくてよいのは、AIに任せる業務がまだ定義できていない場合です。「流行っているから試す」だけでは、モデル比較も費用対効果の判断もできません。まずは、繰り返し発生し、失敗しても回復しやすく、成果を測定できる業務を選ぶべきです。
また、既存のClaudeやGeminiで十分に成果が出ている小規模チームが、MiMo-V2.5-Proの自前運用へ急ぐ必要はありません。オープンウェイトは魅力的ですが、運用負荷を含めると商用APIのほうが安く安全な場合もあります。重要なのは、モデルの話題性ではなく、自社の制約に合うかどうかです。
よくある質問
Xiaomi MiMo-V2.5-Proとは何ですか?
Xiaomi MiMo-V2.5-Proは、Xiaomi MiMoチームが公開したエージェント向け大規模言語モデルです。1.02兆総パラメータ、42BアクティブパラメータのMoEモデルで、最大1Mトークンの長い文脈を扱える点が特徴です。公式には、複雑なソフトウェア開発、長時間タスク、ツール利用を伴うエージェント用途での改善が強調されています。
MiMo-V2.5-ProはClaudeより優れていますか?
一概には言えません。MiMo-V2.5-Proはオープンウェイト、長文脈、エージェント効率で魅力があります。一方、Claude Sonnet 4.6は商用サービスとしての安定性、Claude Codeとの親和性、企業向け運用のしやすさが強みです。自前運用やコスト制御を重視するならMiMo、完成されたAPI体験を重視するならClaudeが候補になります。
Gemini 3.1 Proとの違いは何ですか?
Gemini 3.1 Proは、Googleのマルチモーダル基盤や開発者向けエコシステムと結びついたモデルです。テキストだけでなく画像、動画、PDF、コードリポジトリなどを横断する分析に強みがあります。MiMo-V2.5-Proは、オープンウェイトと長時間エージェント実行に軸足があります。用途がマルチモーダル中心か、開発エージェント中心かで選び方が変わります。
DeepSeek V4-Proと比べるとどちらが安いですか?
2026年4月29日時点では、DeepSeek V4-Proは公式価格表で75%割引が示されており、短期的なAPI単価は非常に競争力があります。ただし割引期限や地域、将来の価格変更を確認する必要があります。MiMo-V2.5-ProはAPI価格だけでなく、MITライセンスと自前運用の可能性を含めて総コストを比較すべきモデルです。
MiMo-V2.5-Proは日本語業務にも使えますか?
使える可能性はありますが、公開情報だけで日本語業務の品質を断定するのは危険です。Hugging Face上では英語・中国語タグが確認できますが、日本語の法務、金融、製造、カスタマーサポートなどでどの程度安定するかは個別検証が必要です。導入前に日本語の実データに近い評価セットを用意し、幻覚、表現品質、専門用語の扱いを確認するべきです。
自社サーバーでMiMo-V2.5-Proを動かせますか?
モデル重みが公開されているため、理論上は自社環境での実行を検討できます。ただし、1.02T総パラメータ、MoE、FP8、1Mコンテキストを実用速度で扱うには大規模なGPU環境と推論最適化が必要です。小規模チームが簡単にローカル実行できるモデルではないため、API利用、クラウドGPU、自前運用の費用と人員を比較する必要があります。
今すぐ導入すべきですか?
すでに長時間の開発エージェントや大量のコード調査で課題があり、評価環境を用意できる組織なら試す価値があります。一方、用途が曖昧なまま本格導入するのはおすすめできません。まずは読み取り専用の検証、過去チケットでの再現テスト、ClaudeやGemini、DeepSeekとの同一タスク比較から始めるのが現実的です。
まとめ
Xiaomi MiMo-V2.5-Proは、1Mコンテキスト、1.02T/42BのMoE構成、MITライセンス、長時間エージェント向けの設計を組み合わせた注目モデルです。特に、複雑なコード作業やツール連携を大量に回す用途では、Claude、Gemini、DeepSeekと並ぶ比較対象になります。
ただし、導入判断では「どのモデルが一番すごいか」よりも、「自社の業務で成功率、再現性、コスト、データ管理、運用負荷のバランスが取れるか」を見るべきです。Claudeは商用エージェント体験、GeminiはマルチモーダルとGoogle基盤、DeepSeekは価格競争力、MiMoはオープンウェイトと長時間エージェント基盤という強みを持ちます。
MiMo-V2.5-Proは、AIモデル競争がチャット品質から「長く働けるエージェントの経済性」へ移っていることを示すモデルです。今後は、ベンチマーク上の性能だけでなく、実際の開発現場でどれだけ安全に、安く、再現性高くタスクを完了できるかが評価の中心になるでしょう。

コメント