
OpenAIは2026年5月7日、Realtime API向けに「GPT-Realtime-2」「GPT-Realtime-Translate」「GPT-Realtime-Whisper」という3つの新しい音声モデルを発表しました。重要なのは、これらが単なる上位・下位モデルではなく、音声エージェント、ライブ翻訳、リアルタイム文字起こしという異なる用途に分かれている点です。音声AIを実務に入れるなら、まず「会話しながら業務を進めたいのか」「通訳したいのか」「文字化したいのか」を切り分ける必要があります。
結論:3モデルは「音声AIの万能モデル」ではなく役割で選ぶ
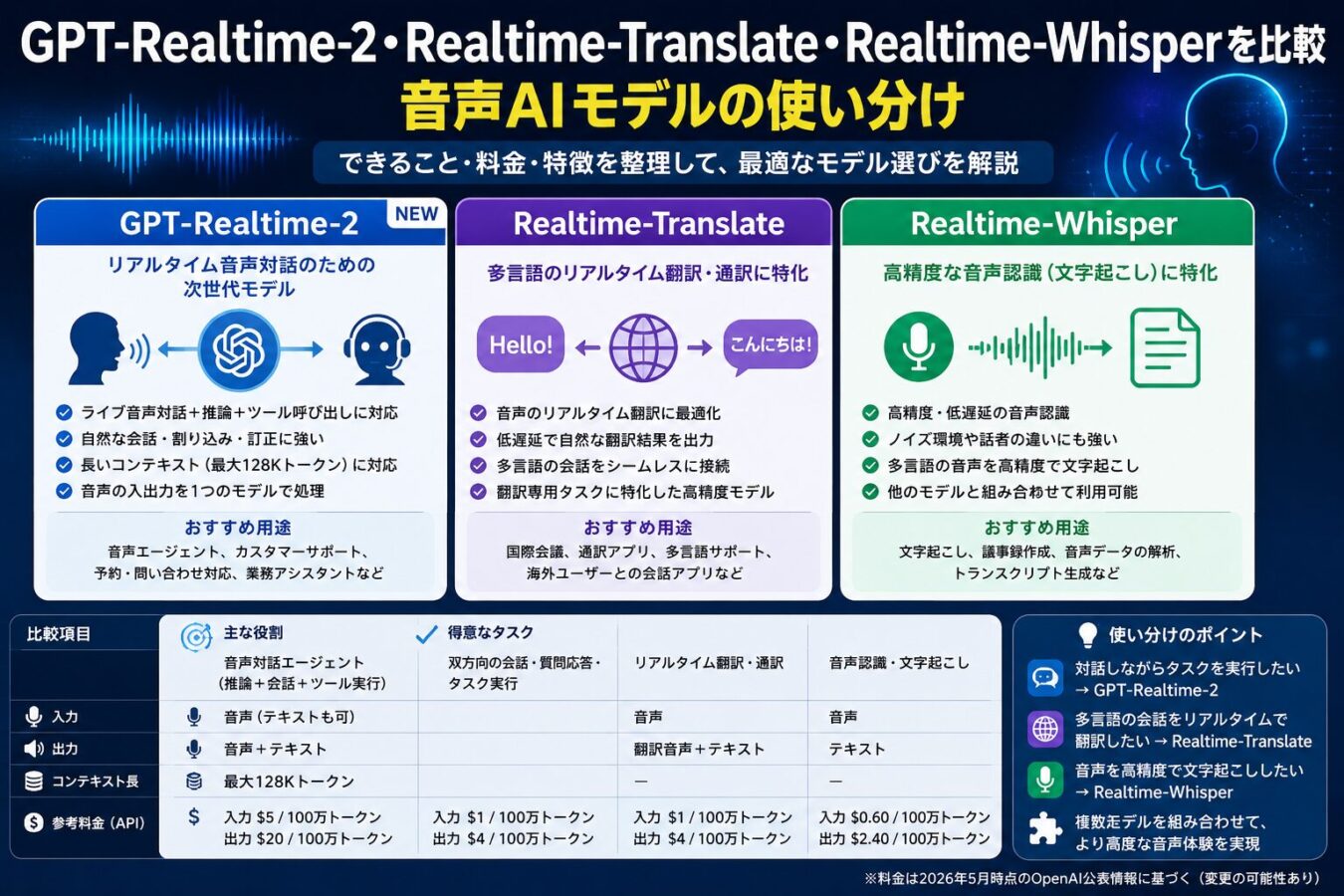
今回の発表で最も誤解しやすいのは、GPT-Realtime-2だけを見れば十分だと考えてしまうことです。GPT-Realtime-2は、音声で対話しながら推論し、必要に応じてツールを呼び出す音声エージェント向けのモデルです。一方、GPT-Realtime-Translateはライブ翻訳、GPT-Realtime-Whisperは低遅延の文字起こしに特化しています。
OpenAIの公式発表では、3モデルはいずれもRealtime APIで利用可能とされています。料金も、GPT-Realtime-2は音声トークン課金、GPT-Realtime-TranslateとGPT-Realtime-Whisperは分単位の課金です。つまり、導入判断では性能だけでなく、入力・出力の形式、遅延、コストの読みやすさ、既存システムとの接続方法まで含めて比較する必要があります。
何が発表されたのか:Realtime API向けの3つの音声モデル
OpenAIは、API向けの新しい音声モデルとして、GPT-Realtime-2、GPT-Realtime-Translate、GPT-Realtime-Whisperを公開しました。公式発表では、これらのモデルは開発者向けのRealtime APIで利用でき、Playgroundでも試せると説明されています。詳しくはOpenAI公式の発表記事で確認できます。
GPT-Realtime-2は、OpenAIのAPI Docsで「realtime voice interactions向けのreasoning model」と説明されており、音声入力、テキスト入力、画像入力に対応し、出力はテキストと音声です。コンテキストウィンドウは128,000トークン、最大出力は32,000トークンとされています。モデルページでは、設定可能なreasoning effort、より強い指示追従、複雑な音声エージェントワークフローでのツール利用が特徴として挙げられています。
GPT-Realtime-Translateは、ライブ多言語音声体験のためのストリーミング音声翻訳モデルです。専用のRealtime translation endpointを使い、入力音声が届いている最中に翻訳音声とテキストの差分を返す設計です。OpenAIのRealtime translationガイドでは、会議、授業、動画ルーム、多言語通話、配信などが用途として挙げられています。
GPT-Realtime-Whisperは、低遅延の音声認識、つまりリアルタイム文字起こしのためのモデルです。OpenAIのRealtime transcriptionガイドでは、ライブ音声、 transcript deltas、調整可能なレイテンシが必要な場面に向くと説明されています。ただし、すべての文字起こし用途を置き換えるものではなく、実際の音声、言語、語彙、遅延要件で検証すべきとも明記されています。
3モデルの基本比較:用途・入出力・料金の違い
| モデル | 主な用途 | 入力 | 出力 | 料金 | 向いているケース |
|---|---|---|---|---|---|
| GPT-Realtime-2 | 音声エージェント、音声対話、ツール実行 | テキスト、音声、画像 | テキスト、音声 | 音声入力100万トークンあたり32ドル、音声出力100万トークンあたり64ドル。テキスト入力は100万トークンあたり4ドル、テキスト出力は24ドル | 予約変更、問い合わせ対応、業務アシスタント、本人確認を含む対話型フロー |
| GPT-Realtime-Translate | ライブ翻訳、通訳 | 音声 | 翻訳音声、テキスト | 1分あたり0.034ドル | 国際会議、多言語サポート、動画通話、配信、教育 |
| GPT-Realtime-Whisper | リアルタイム文字起こし | 音声、テキスト | テキスト | 1分あたり0.017ドル | ライブ字幕、議事録、通話ログ、授業・イベントの文字化 |
この比較から分かる通り、3モデルは「高性能なものを1つ選ぶ」というより、音声体験のどの部分を担わせるかで選ぶモデルが変わります。たとえば、多言語の問い合わせ窓口を作る場合、ユーザーとの会話と業務システム操作にはGPT-Realtime-2、通訳に近い音声変換にはGPT-Realtime-Translate、後から検索できる記録作成にはGPT-Realtime-Whisperを組み合わせる選択肢があります。
背景:音声AIは「聞く・話す」から「会話中に行動する」段階へ進んだ
従来の音声AIは、音声認識でテキスト化し、LLMで回答を生成し、TTSで読み上げるという分割型の構成が一般的でした。この構成でも多くの用途は実現できますが、遅延が大きくなりやすく、会話の途中で割り込まれたときの処理や、声のニュアンスを保った自然な応答には課題が残ります。
OpenAIは2025年にも本番向け音声エージェント用のRealtime API更新を発表し、音声を単一のモデルとAPIで直接処理することで、遅延を抑え、音声のニュアンスを保持しやすくなると説明していました。今回のGPT-Realtime-2は、その流れをさらに進め、推論、長文脈、ツール呼び出し、短い発話による待機感の軽減まで含めて、音声エージェントをより業務フローに近づける更新と見られます。
Reutersも、今回の発表について、OpenAIが文字起こしやチャットを超えて、ライブ会話中に聞き、翻訳し、行動できるソフトウェアエージェントへ進んだと報じています。報道では、Zillow、Priceline、Deutsche Telekomなどがテスト顧客として挙げられています。ただし、個別企業での本番導入範囲や成果の詳細は、公開情報だけでは限定的です。
GPT-Realtime-2で何ができるようになるのか
GPT-Realtime-2の大きな進歩は、音声で話している最中の対話を、単なる入出力ではなく「作業の進行」として扱いやすくなる点です。OpenAIのRealtime prompting guideでは、GPT-Realtime-2は考えてから話すことができ、より大きなコンテキストを使い、以前のRealtimeモデルより精度高くツールを呼び出せると説明されています。
たとえば、旅行予約の変更を音声で依頼された場合、従来の音声ボットは「目的地」「日程」「予約番号」を順番に聞き取り、テキスト化してから別システムに渡す必要がありました。GPT-Realtime-2を使う構成では、会話の流れを維持しながら必要な情報を確認し、空席確認や変更手続きのツールを呼び出し、処理中に「確認します」といった短い発話を挟む設計がしやすくなります。
また、128,000トークンのコンテキストウィンドウは、長時間の会話や大きめの業務ルール、顧客情報、過去のやり取りを扱ううえで意味があります。ただし、長文脈を入れれば自動的に賢くなるわけではありません。OpenAIのガイドでも、長いセッションでは、どの情報が現在有効で、どれが背景情報で、どれを無視すべきかを構造化する必要があると説明されています。
Realtime-Translateで何ができるようになるのか
GPT-Realtime-Translateは、一般的な音声モデルに「翻訳して」と頼む使い方とは少し違います。OpenAIのCookbookでは、このモデルはプロの通訳音声を含む学習により、翻訳だけに留まり、十分な文脈を待ってから発話するよう最適化されていると説明されています。文章構造が異なる言語間では、話し始めの単語だけで即座に訳すと意味が崩れるため、この性質は重要です。
従来のライブ翻訳では、話者が区切って話す、通訳側の処理を待つ、翻訳文の表示と音声出力がずれる、といった問題が起きがちでした。Realtime-Translateは、入力音声を処理しながら翻訳音声をストリーミングで返す設計のため、配信、ウェビナー、国際会議、多言語カスタマーサポートのような場面で、より自然な会話体験を作りやすくなります。
一方で、これは音声エージェントではありません。OpenAIの翻訳ガイドでは、音声エージェントを作るならGPT-Realtime-2を使うべきだと明示されています。つまり、翻訳中に注文変更、本人確認、CRM更新まで行わせたい場合は、Translate単体ではなく、Realtime-2や外部システムとの設計が必要になります。
Realtime-Whisperで何ができるようになるのか
GPT-Realtime-Whisperは、話者が話している最中に低遅延で文字起こし差分を返すためのモデルです。ライブ字幕、会議の途中メモ、授業やイベントのリアルタイム表示、通話内容の即時ログ化に向いています。OpenAIのモデルページでは、音声時間による課金であり、文字数やトークンではなく分単位で見積もりやすい点も特徴です。
ただし、リアルタイム性と精度はしばしばトレードオフになります。OpenAIのRealtime audio guideでは、低い遅延設定は早い部分文字起こしを出しやすい一方、高い遅延設定は文字起こし品質の改善につながる可能性があると説明されています。騒音のある環境、専門用語が多い会議、複数話者が重なる場面では、本番導入前の実音声テストが不可欠です。
また、録音済みファイルを高精度に文字起こしするだけなら、GPT-4o Transcribeや既存のWhisper系モデルが適する場合もあります。Realtime-Whisperは「ライブで差分を受け取りたい」用途に強い一方、後処理で時間をかけられるワークフローでは、別のモデルやバッチ処理のほうが費用対効果に優れる可能性があります。
既存競合との比較
比較1:GPT-Realtime-2とGPT-Realtime-1.5
GPT-Realtime-1.5は、低遅延で信頼できる非推論系のspeech-to-speechモデルとして位置づけられています。OpenAIのプロンプトガイドでは、最も強いリアルタイム推論、ツール利用、指示追従が必要ならGPT-Realtime-2、速く信頼できる非推論の音声対話ならGPT-Realtime-1.5という使い分けが示されています。
料金面では、GPT-Realtime-2のテキスト入力は100万トークンあたり4ドル、テキスト出力は24ドルで、音声入力は32ドル、音声出力は64ドルです。音声エージェントのタスクが単純なFAQ応答や簡単な受付だけなら、必ずしも最上位の推論モデルを使う必要はありません。逆に、予約変更、規約確認、本人確認、複数ツールの呼び分けがある場合は、Realtime-2の価値が出やすくなります。
比較2:GPT-Realtime-Translateと一般目的の音声モデルによる翻訳
一般目的の音声モデルでも、プロンプトで「翻訳してください」と指示することはできます。しかしOpenAIのCookbookでは、一般目的の音声モデルは質問に答えたり指示に従ったりしてしまい、翻訳だけに徹しない可能性があると説明されています。翻訳専用のRealtime-Translateは、通訳用途に最適化されている点が差別化です。
価格面でも、Realtime-Translateは1分あたり0.034ドルと時間単位で見積もれます。イベント配信や多言語会議のように、時間が明確な用途では費用計算がしやすい一方、翻訳以外の業務処理を含めたい場合は、GPT-Realtime-2との組み合わせが必要です。
比較3:GPT-Realtime-WhisperとGPT-4o Transcribe、Whisper-1
Realtime transcriptionガイドでは、GPT-Realtime-Whisperはライブ音声、文字起こし差分、調整可能なレイテンシに向くモデルとされます。一方、GPT-4o Transcribeはストリーミングが必須でない高精度な音声文字起こし、GPT-4o mini Transcribeはコスト重視、Whisper-1は既存Whisper連携向けという位置づけです。
つまり、会議後に録音ファイルをアップロードして議事録化するなら、必ずしもRealtime-Whisperである必要はありません。ライブ字幕、通話中の要約、即時検索、通話後すぐのフォローアップなど、リアルタイム性が事業価値に直結する場合に選ぶべきモデルです。
比較4:従来のSTT+LLM+TTS構成との違い
従来構成の利点は、部品を自由に差し替えられることです。音声認識、LLM、音声合成を別々に選べるため、コスト最適化やベンダー分散がしやすい場合があります。既に社内で音声認識基盤や翻訳基盤を持っている企業では、既存構成をすぐに置き換える必要はありません。
一方で、分割型の構成は、各処理の間に遅延が積み重なりやすく、割り込み、言い直し、会話のニュアンス、ツール実行中の自然な発話を扱いにくい傾向があります。Realtime APIのような統合型の音声モデルは、自然な会話体験を優先する場合に有利です。ただし、ブラックボックス性やベンダーロックイン、モデル変更時の挙動差には注意が必要です。
懸念点・注意点:本番導入で見落としやすいポイント
第一の注意点は、音声AIでは「少し間違える」ことの影響が大きい点です。電話番号、住所、予約日、薬剤名、金額、契約条件などを聞き間違えると、単なるチャットの誤字よりも業務影響が大きくなります。OpenAIのガイドでも、重要な書き込み操作の前には確認境界を明確にすることが推奨されています。
第二に、レイテンシと推論の深さはトレードオフになり得ます。GPT-Realtime-2ではreasoning effortを設定できますが、深い推論は遅延や出力トークン使用量を増やす可能性があります。顧客対応のように待ち時間に敏感な場面では、すべてを高推論にするのではなく、失敗コストが高いタスクだけ推論を厚くする設計が現実的です。
第三に、データの扱いと地域要件です。OpenAIのData controlsでは、gpt-realtime-2、gpt-realtime-translate、gpt-realtime-whisperがUSとEUに対応する一覧に含まれています。ただし、各社の規制、契約、個人情報保護、録音同意の要件は別途確認が必要です。特に通話録音や医療・金融・採用での利用は、モデル性能だけで導入判断できません。
第四に、移行時の互換性です。OpenAIのDeprecationsページでは、Realtime API Betaや古いrealtime preview系モデルの終了情報が示されています。既存のrealtime preview連携がある場合、単にモデル名を差し替えるだけでなく、セッション設計、プロンプト、ツール呼び出し、イベント処理を確認する必要があります。
導入メリットを得やすい人・組織
向いているケース
最も相性がよいのは、音声で完結する問い合わせが多く、かつ単純なFAQでは終わらない業務を持つ組織です。たとえば、予約変更、配送状況確認、本人確認後の手続き、契約内容の確認、社内ヘルプデスクなどは、GPT-Realtime-2のツール呼び出しや長い会話文脈が価値を出しやすい領域です。
多言語対応がボトルネックになっている組織には、Realtime-Translateが向きます。国際イベント、越境EC、ホテル、教育機関、海外顧客を持つSaaS企業では、通訳者の確保や対応時間の制約を補える可能性があります。ただし、法的・医療的に正確性が強く求められる場面では、人間のレビューやエスカレーションを前提にした設計が必要です。
会議や通話の内容をリアルタイムに活用したい組織には、Realtime-Whisperが向きます。単なる議事録ではなく、発話中に字幕を出す、会話の途中で重要語を拾う、サポート通話から即時にCRMへメモを流す、といった用途では、ライブ文字起こしの価値が出ます。
現時点では向いていないケース
音声体験そのものが事業価値に直結しない場合、導入を急ぐ必要はありません。たとえば、月に数回の会議録作成、録音ファイルの後処理、社内の小規模な問い合わせ対応だけなら、既存の文字起こしモデルやチャットボットで十分な可能性があります。
また、正確性の担保、録音同意、個人情報のマスキング、人間への引き継ぎフローが未整備の組織も慎重に進めるべきです。音声AIはユーザーが自然に話せる分、想定外の個人情報や機密情報が入力されやすくなります。プロトタイプ段階でも、ログ保存、アクセス権限、削除ポリシーを先に決めておく必要があります。
実務導入を判断する際のポイント
まず確認したい前提条件
最初に確認すべきなのは、導入対象が「音声である必然性」を持っているかです。ユーザーが移動中、作業中、電話中でキーボードを使えない場合は音声AIの価値が出ます。一方、画面で選択したほうが早い手続きや、証跡が重要な承認業務では、音声だけで完結させるより、画面UIと併用するほうが安全です。
導入判断で見るべき5つの観点
- 精度: 一般的な会話精度ではなく、固有名詞、住所、日付、金額、専門用語をどれだけ安定して扱えるかを確認する。
- 遅延: 平均応答時間だけでなく、ツール呼び出し時、翻訳時、騒音環境での体感待ち時間を測る。
- コスト: Realtime-2の音声トークン課金と、Translate・Whisperの分課金を分けて試算する。
- データの取り扱い: 録音、文字起こし、会話ログ、個人情報、EUデータ residency要件を整理する。
- 障害時の代替手段: AIが聞き取れない、ツールが失敗する、ユーザーが怒る、規約上の判断が必要になる場合の人間引き継ぎを決める。
試験導入から本格導入までの見方
試験導入では、まず1つの限定業務に絞るべきです。たとえば「配送状況の確認だけ」「会議字幕だけ」「英語から日本語の社内ウェビナー翻訳だけ」のように、成功条件を測りやすい単位にします。最初から全問い合わせを任せると、失敗原因がモデル、プロンプト、業務フロー、音声環境のどこにあるか分からなくなります。
本格導入の判断では、成功率だけでなく、失敗時の回復率を見ます。音声AIでは、1回の聞き間違いよりも、聞き間違いに気づいて確認し直せるか、誤ったツール実行を防げるか、人間に適切に渡せるかが重要です。GPT-Realtime-2のような推論モデルを使う場合も、重要操作前の復唱や確認は省略すべきではありません。
導入を急がなくてよいケース
音声対応の問い合わせが少ない、利用者が画面操作に慣れている、通話録音や個人情報の社内ルールが未整備、既存のFAQチャットで十分に解決できている場合は、急いで本番導入する必要はありません。まずはRealtime-Whisperで会話ログを可視化し、どの業務が音声エージェント化に向くかを分析する段階から始める選択肢もあります。
よくある質問
GPT-Realtime-2とRealtime-Translateはどちらを使えばいいですか?
音声で会話しながら予約変更、問い合わせ対応、ツール実行まで行いたいならGPT-Realtime-2が候補です。一方、主目的が通訳やライブ翻訳で、入力された音声を別言語の音声とテキストに変換したいならRealtime-Translateが適しています。翻訳しながら業務処理も行う場合は、両者を組み合わせる設計を検討します。
GPT-Realtime-WhisperはWhisper-1の完全な置き換えですか?
完全な置き換えではありません。OpenAIのガイドでも、GPT-Realtime-Whisperはライブ文字起こし向けの選択肢であり、すべての文字起こしモデルを置き換えるものではないと説明されています。録音ファイルを後から高精度に処理する用途では、GPT-4o Transcribeや既存のWhisper-1が適する場合もあります。
料金はどのモデルが一番安いですか?
単純比較はできません。GPT-Realtime-2は音声トークン課金で、入力と出力の長さ、会話内容、キャッシュ利用によって費用が変わります。Realtime-Translateは1分あたり0.034ドル、Realtime-Whisperは1分あたり0.017ドルです。ライブ字幕だけならWhisperが見積もりやすく、対話と業務処理を含むならRealtime-2の費用対効果を見る必要があります。
日本語の音声対応でも使えますか?
公開情報上、Realtime-Translateは70以上の入力言語から13の出力言語への翻訳をサポートすると説明されています。ただし、モデルごとの日本語精度、固有名詞、方言、騒音環境での実力は、実際の音声データで検証する必要があります。特に顧客名、住所、商品名、専門用語が多い業務では、事前テストが不可欠です。
音声エージェントをすぐ本番導入しても大丈夫ですか?
いきなり全面導入するより、限定業務で試験導入するのが安全です。重要操作の前に確認を挟む、聞き取れない場合の聞き返し、人間へのエスカレーション、ログの保存と削除、個人情報の扱いを先に決める必要があります。音声は自然に使える分、想定外の入力や機密情報が入りやすい点にも注意が必要です。
GPT-Realtime-2を使えば従来のSTTやTTSは不要になりますか?
すべて不要になるわけではありません。統合型のRealtime APIは自然な対話や低遅延に強みがありますが、既存のSTT、LLM、TTS構成は部品ごとの最適化やベンダー分散がしやすい利点があります。音声体験の自然さを重視するならRealtime系、コストや統制を細かく管理したいなら分割構成も候補に残ります。
まとめ:モデル名ではなく「音声で何をしたいか」から選ぶ
GPT-Realtime-2、GPT-Realtime-Translate、GPT-Realtime-Whisperは、いずれもOpenAIの音声AI戦略を一段進めるモデルですが、役割は明確に異なります。GPT-Realtime-2は音声エージェント、Realtime-Translateはライブ翻訳、Realtime-Whisperはリアルタイム文字起こしに向きます。
実務導入で重要なのは、最も新しいモデルを選ぶことではありません。ユーザーが音声で何をしたいのか、AIにどこまで業務を任せるのか、誤認識時にどう回復するのか、費用をどの単位で管理するのかを先に決めることです。音声AIは、チャットの読み上げ版ではなく、会話中に理解し、判断し、必要に応じて行動するインターフェースへ進みつつあります。
現時点で注目すべき読者は、カスタマーサポート、予約・問い合わせ業務、教育、イベント配信、会議記録、多言語対応を抱える組織です。一方で、規制、個人情報、正確性が重要な業務では、人間の確認とエスカレーションを前提に、段階的に検証するのが現実的です。
参考ソース
- OpenAI: Advancing voice intelligence with new models in the API
- OpenAI API Docs: gpt-realtime-2 model
- OpenAI API Docs: gpt-realtime-translate model
- OpenAI API Docs: gpt-realtime-whisper model
- OpenAI API Docs: Using realtime models
- OpenAI API Docs: Realtime translation
- OpenAI API Docs: Realtime transcription
- OpenAI API Docs: Data controls in the OpenAI platform
- OpenAI API Docs: Deprecations
- Reuters: OpenAI unveils three audio models for real-time voice tasks

コメント